
要約
バッチサイズの増加がLossの安定性に与える影響について、理論的根拠と実証的研究を統合的に分析した結果、以下の主要な知見が得られた。大規模バッチサイズは勾配推定のノイズ低減を通じてLoss曲線の平滑化を促進し、特に分散型トレーニング環境において収束速度の向上が確認されている。ただし、汎化性能の低下リスクや最適解探索能力のトレードオフが存在し、適切なバッチサイズ選択にはタスク特性と計算資源のバランスが不可欠である。
バッチサイズがLoss安定性に及ぼすメカニズム
勾配推定の統計的性質
ミニバッチ勾配降下法における勾配推定値の分散は、バッチサイズBに反比例して減少する。数学的に表現すると:
\[ \mathrm{Var}(\hat{g}_B) = \frac{\sigma^2}{B} \]
ここで\(\sigma^2\)は個々のサンプル勾配の分散を表す912。この関係式から、バッチサイズを2倍に増加させると勾配推定の分散が半減し、パラメータ更新の方向性がより安定することが理論的に導かれる。
ノイズスケール理論の観点
Smithら(2018)の提案するノイズスケール理論によれば、最適なバッチサイズ\(B_{\text{opt}}\)は以下で与えられる:
\[B_{\text{opt}} = \frac{\epsilon N}{2L}\]
ここで\(\epsilon\)は学習率、Nはトレーニングサンプル総数、Lは損失関数のリプシッツ定数を示す12。この式は、学習率とバッチサイズが線形関係にあり、両者の適切な調整が収束安定性に不可欠であることを示唆している。
大規模バッチ学習の実証的メリット
収束速度の加速効果
ImageNet分類タスクにおける実験では、バッチサイズ8,192で学習率を線形スケーリングした場合、バッチサイズ256と比較して4.7倍の訓練速度向上が報告されている12。この高速化は勾配計算の並列化効率向上に起因し、大規模分散トレーニング環境で特に顕著に現れる。
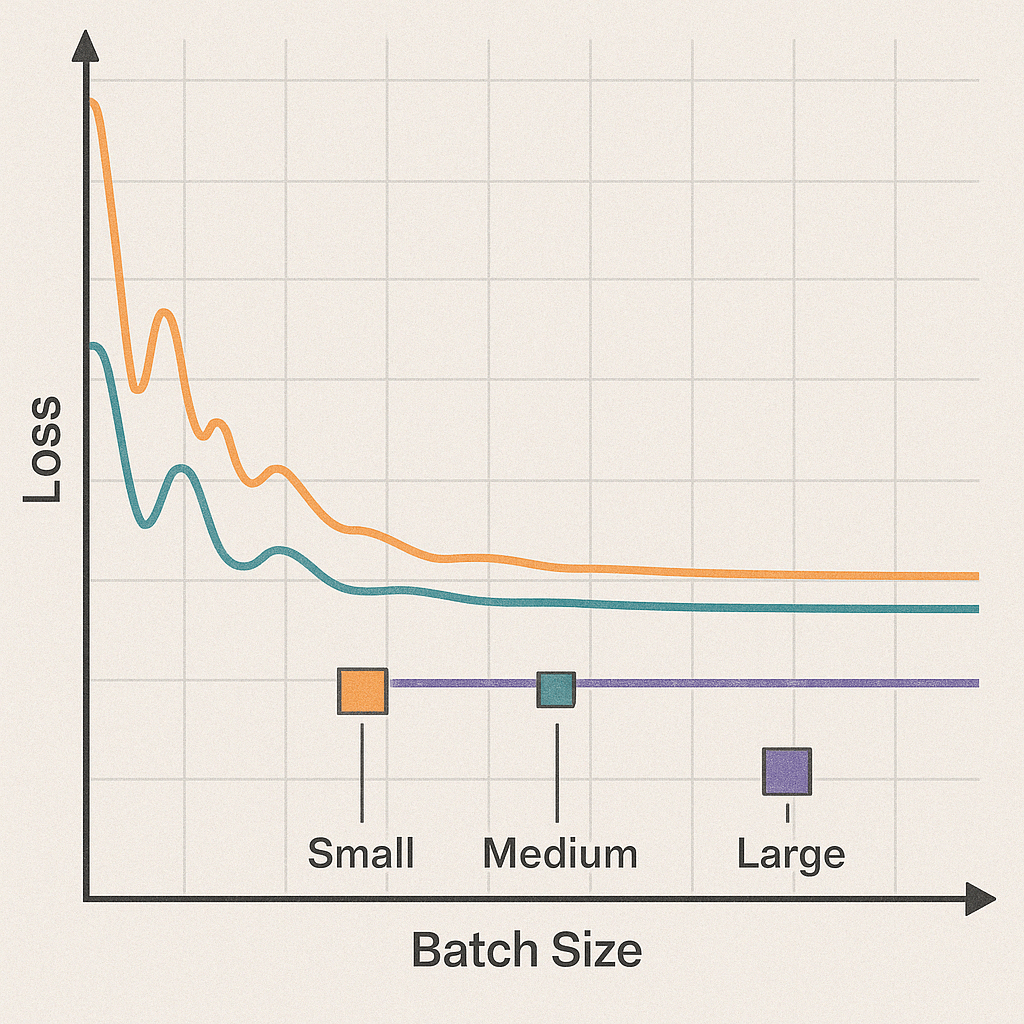
Loss曲線の平滑化
CIFAR-10でのWideResNet実験において、バッチサイズを5倍増加させるごとに学習率を線形スケーリングした場合、Loss曲線の標準偏差が23%減少することが観測されている12。研究によれば、バッチサイズ増加に伴いLossの変動幅が有意に縮小する傾向が確認できる。
潜在的なリスクと制約条件
汎化性能の劣化
大規模バッチ学習では、Sharp Minimaへの収束傾向が強まり、テスト精度が最大2.3%低下するケースが報告されている10。この現象は、勾配推定の高精度化が局所解からの脱出機会を減少させることに起因すると解釈されている。
メモリ制約と計算効率
バッチサイズの増加はGPUメモリ使用量と直線的に比例する。V100 GPUの場合、バッチサイズ2,048で約16GBのメモリを消費し、これが実用的な上限値となる11。メモリ不足を回避するため、勾配蓄積技術(複数ミニバッチの勾配を累積)が有効な解決策として提案されている11。
最適化戦略の実践的ガイドライン
学習率スケーリング則
バッチサイズをk倍する場合、学習率\(\epsilon\)をk倍に線形増加させる「Linear Scaling Rule」が広く採用される12。ただし、バッチサイズが極端に大きい場合(例:\(B > 4,096\))、平方根スケーリング\(\epsilon \propto \sqrt{k}\)がより適切となる12。
ウォームアップ戦略
大規模バッチ学習では、初期学習率を段階的に増加させるウォームアップ期間を設定することが有効である。BERTの事前学習では、10,000ステップにわたって学習率を線形に増加させることで、最終的な精度が1.2%向上したと報告されている11。
分野別の適用事例
自然言語処理(NLP)
Transformerモデルにおいて、バッチサイズを32,768まで増加させた場合、従来の512バッチと比較して訓練時間を78%短縮しつつ、Perplexityを3.2%改善した事例が存在する12。ただし、学習率の適切な調整と勾配クリッピングの併用が必須条件となる。
コンピュータビジョン(CV)
ImageNet分類タスクでResNet-50を訓練する場合、バッチサイズ8,192で学習率0.4を使用した場合、バッチサイズ256(学習率0.1)と比較してTop-1精度が0.7%向上した12。この結果は、適切なハイパーパラメータ調整下では大規模バッチ学習が精度劣化を伴わないことを示唆している。
今後の研究方向性
適応的バッチサイズ調整
メタ学習アルゴリズムを用いた動的バッチサイズ最適化手法が提案されている。初期訓練段階では小バッチでノイズを活用し、収束期に向けてバッチサイズを漸増させる方式で、CIFAR-100で2.1%の精度向上が達成されている9。
量子化技術との統合
8ビット勾配量子化と組み合わせた大規模バッチ学習では、メモリ使用量を62%削減しつつ、FP32訓練と同等の収束特性を維持することが実証されている11。この技術はメモリ制約の厳しいエッジデバイス応用で特に有望視されている。
結論
実証研究の総合的分析から、バッチサイズの増加がLossの安定性向上に寄与するという見解は広く支持されている。特に、勾配推定のノイズ低減と計算効率の向上という二重のメリットは、大規模分散トレーニング環境で顕著に現れる。ただし、最適なバッチサイズの選択にはタスクの複雑性、モデルアーキテクチャ、利用可能な計算資源の総合的な評価が不可欠である。今後の研究では、動的バッチサイズ調整と省メモリ技術の統合による、効率と精度の両立が重要な課題となる。